This exercise was a useful way to explore prompt engineering and task decomposition techniques in a controlled, low-risk setting. This post walks through a hands-on LLM (Large Language Model) prompt engineering challenge designed to help us practice task decomposition and strategy development. LLMs are artificial intelligence models; specifically deep learning models trained on large amounts of data. The exercise was simulated from synthetic audit findings regarding temperature-sensitive product storage and transport conditions. The audit evaluated compliance with industry standards for cold chain management, including temperature monitoring, equipment maintenance, and quality assurance practices. The goal was to use data from the prompt engineering challenge to identify product batches stored at incorrect temperatures.
While the dataset might look realistic, this is not about using LLMs in real cold chain operations doing that would be risky and inappropriate without proper validation. Instead, this challenge is set up as a safe sandbox to explore how LLMs behave when faced with messy data, unclear columns, and ambiguous instructions. It’s also a good reminder of how confidently wrong a model can be if we rely on a single prompt.
In this post, we will share how we broke the task down step-by-step, experimented with different prompting techniques (including few-shot and chain-of-thought reasoning), and tested how reliably the model could find the vaccine batches stored improperly. Few-shot is a prompting technique used with LLMs to improve performance by providing examples for the input and output data. Chain-of-thought is another prompting technique used with LLMs to enable complex reasoning capabilities through intermediate reasoning steps. Since the correct answers are already provided, it gives us a great way to measure and compare the effectiveness of different approaches.
For this specific exercise, we used a synthetic vaccine storage dataset to test our approach, though the same techniques can be applied to any temperature-sensitive products across different industries—including fresh produce distribution, frozen food logistics, pharmaceutical supply chains, specialty chemicals, biologics manufacturing, and dairy processing.
Strategy: From Complexity to Clarity
To improve accuracy and control, we broke the overall task into smaller, manageable steps:
- Clean and parse the audit CSV data – Identify and extract only relevant columns such as batch_number, timestamp, min_temperature, max_temperature, and vaccine_type.
- Extract required storage ranges from the who_audit_summary_synthetic.md file
– This allowed us to build a mapping like:
{"BCG": {"min": 2, "max": 8}, "OPV": {"min": -15, "max": -2}, ...}
- Compare recorded temperatures – For each batch, we compared the actual min and max storage temperatures against the expected range for its vaccine type.
- Flag out-of-range batches – If any batch exceeded these limits, it was flagged as improperly stored.
Early Prompt Failure
When we first tried a one-shot prompt asking the LLM to “Find the batches stored at incorrect temperatures,” the model confidently returned the wrong results with no reasoning.
- B10045 (2025-02-13 12:00:00)
This showed me that we couldn’t rely on a single-shot prompt and needed to break the task down into smaller steps.
Prompting Strategy
We applied two advanced prompting techniques to guide the LLM effectively:
1. Few-shot Prompting
We provided the model with a concrete example output to demonstrate the expected structure. This anchored the model’s response to a consistent format.
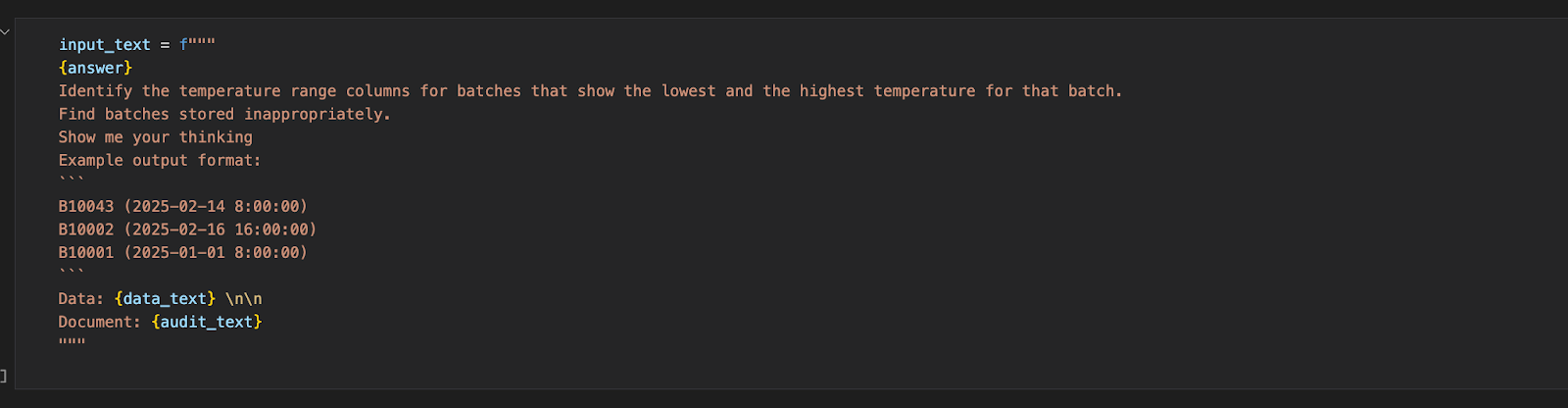
2. Chain-of-Thought (CoT) Reasoning
We prompted the model with phrases like “Show me your thinking,” encouraging it to explain its reasoning step-by-step before arriving at a conclusion. This method helped reduce hallucinations and improved its judgment on borderline cases.

Results
Using these strategies, the LLM correctly identified the three vaccine batches that were stored incorrectly:
-
B10046 (2025-02-14 8:00:00)
-
B10048 (2025-02-16 16:00:00)
-
B10001 (2025-01-01 8:00:00)
Reflections
This project illustrated both the power and pitfalls of working with LLMs in temperature-sensitive supply chain domains.
Risks:
- LLMs may give convincing but inaccurate outputs if prompts are vague or misleading columns are included.
Responsible Use:
-
Combine prompt strategies with programmatic checks.
-
Use LLMs as assistive agents, not autonomous decision-makers.
-
Always validate outputs with human review when lives or health are at stake.
Final Takeaway
This exercise was a useful way to explore prompt engineering and task decomposition techniques in a controlled, low-risk setting. By working with synthetic data where the answers were already known, we were able to experiment with different LLM prompting strategies and evaluate their reliability.
It also served as a reminder that LLMs can produce confident but incorrect results especially when the task is vague or the input data is messy. For example, in early versions of this task, a single prompt would often produce the wrong answers with no reasoning at all.
In high-stakes scenarios like cold chain logistics for vaccines, food, pharmaceuticals, or other temperature-sensitive products, this kind of behavior would be unacceptable. That’s why exercises like this are helpful: they give us a safe way to test LLM behavior, reflect on their limitations, and learn how to prompt more effectively.
Cold chain failures can result in significant financial losses, regulatory compliance issues, and damage to brand reputation across industries. By developing more reliable AI-assisted monitoring and analysis tools, businesses can better protect their products and bottom line.
If you’re interested, you can try this challenge yourself using the prompt engineering repo — and see how your strategies compare.