Hi folks,
I wanted to post a little update about a big new feature in the core runtime: source positions in errors!!
This affects the Worker 1.9.0 (live on app right now and bundled with Lightning 2.10.10) and CLI 1.10.0
What Am I Looking At?
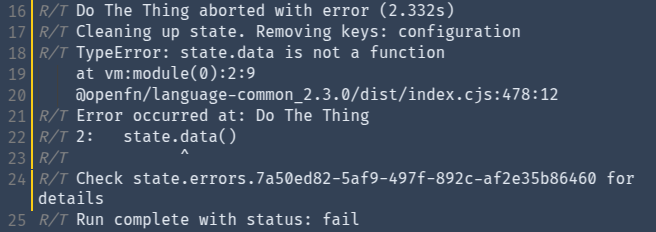
The screenshot above is a little bit dense so I’ll take a minute to explain it.
This is the run log for a silly workflow I created which tries to call state.data(). But state.data is not a function, we cannot invoke it, and so this results in a runtime exception. The workflow is called Do The Thing, because it’s just a demo and I’m hilarious.
On line 18, you’ll see the error message: TypeError: state.data is not a function.
And immediately below it, you’ll see a stack trace, showing the callstack at which the error occurred and the line and column offset for each frame. The vm:module(0) stuff is what the execution context of the job code is called - that’s just what JavaScript calls it (we might fix this later, now that it’s exposed). And it tells us that the error occurred on line 2, column 9.
Below that is the stack trace coming from the adaptor code. This probably isn’t terribly useful for us right now - but with my special inside knowledge I can tell you that it’s referring to the source code of the common fn() function.
Then on line 22, we print the source line which triggered the error, with a little marker to show the exact location. Because counting column offsets in plain text is not something that humans are good at.
What Problem Does this solve?
Up until very recently, errors coming out of workflows will report an error message (well, if you’re lucky), but NOT report the position of that error. Or any other useful context, really.
Sometimes, if you were really really lucky, you’d see a stack trace coming out of the runtime code itself - out of our runtime environment. Which is open source, and not a secret, but also not something that users should be exposed to.
Anyway for small jobs this was sort of fine, you could usually figure out where the error came from. But when your job creeps up to 10, 50, 100, 500 lines (and they easily can if you include lookup tables and stuff), it becomes impossible to track down where the problem occurred.
But if you’re reading this, you’re probably all too aware of that.
Why was this difficult?
In regular JavaScript code, errors always come with a position and stack trace. So why has it taken us all this time to be able to show the position of your errors?
There are two answers to that. One is compilation, and one is the VM (or virtual machine) of our runtime.
Let’s quickly handle compilation. The code you write in a job is not technically valid, executable JavaScript. You can’t copy and paste it into your browser’s devtools. That’s because we compile it - we transform it - into portable JavaScript. There are two big changes we make to the code: first we add import and export statements to import adaptor functions. And secondly we move all the operations in your code into an array and export it, so that they can be executed as a pipeline of functions. For example, we convert fn(s => s) into export default [fn(s => s)].
That process of compilation means that the code we run is different to the code you write, and so the positions get all messed up. We have map the runtime error positions back to the source code.
The other one is the VM, which I’ve sort of mentioned already. Your job code runs in an isolated sandbox inside a JavaScript Environment. When we execute your code, we load it into a regular node.js engine, turn it into a module, and execute it. That means there are two JavaScript environments: ours (which you can think of as the CLI or Worker, both JavaScript projects in kit), an yours (everything inside your job code).
When we report errors and stack traces and stuff, we don’t want to confuse users by showing errors from OUR code. The stack trace of our runtime engine is not useful to users. It’s barely useful to us - if the error occurred inside job code, then the stack will point to the runtime’s execute() function which executes your code. Big deal. We don’t care about the stack at this point.
You can check out the PR in the underlying runtime if you like - although it probably for expert JavaScript eyes only. The worst bit is the sheer breadth of it - how many bits of the source code these changes touch. Anyway, the PR is available for all to see at github.com/OpenFn/kit/pull/848
That’s all from me. This was a really important and exciting feature to bring into release. Let us know how you get on! There are likely to be cases where we don’t handle errors terribly well, so do let us know if you encounter one of this.