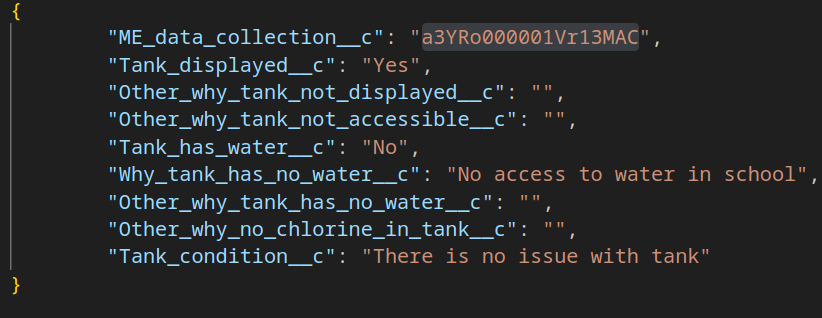
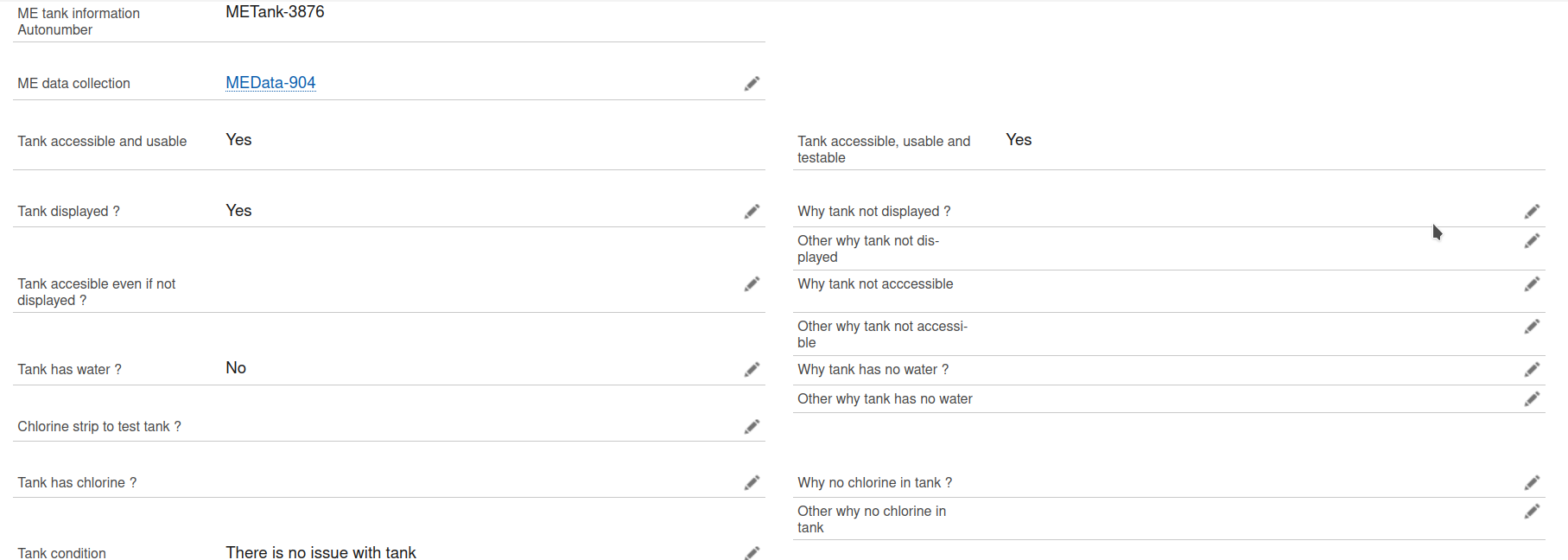
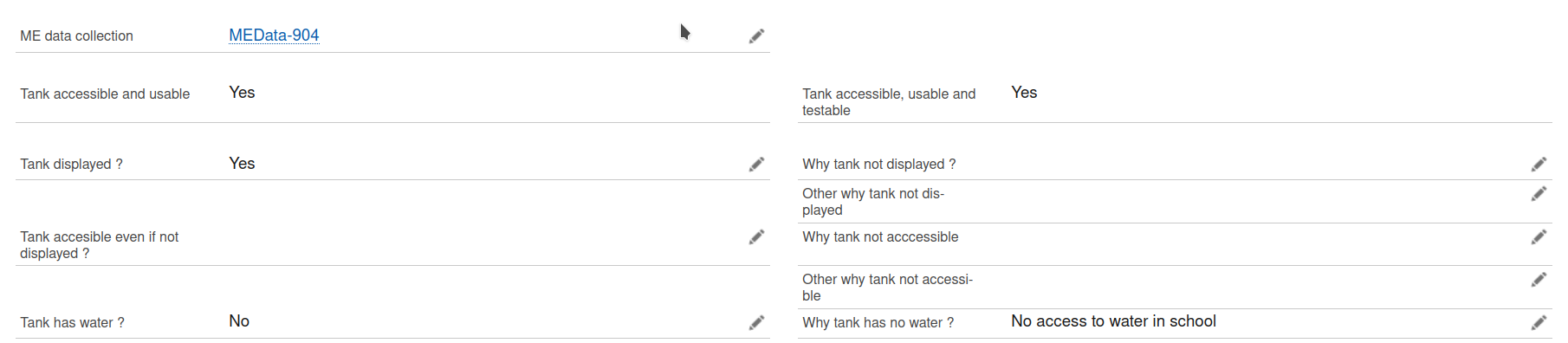
Hi all, when trying to insert records using the Salesforce adaptor version 4.6.2, there are some fields that are not updated despite being in the final JSON before the insert. There is also no error message that indicates the field wasn’t updated. In the JSON screenshot, for example, the field Why_tank_has_no_water__c? is filled, but it is not reflected in Salesforce (Why tank has no water ?). There are other fields where this has happened as well. Do you know what could be the problem? Thank you.
@djohnson strange that there is no error message! Could you (1) confirm which adaptor function you’re using (e.g., insert, bulk) and (2) share a snippet of your job code to see if we can spot any issue?
Then, is there any chance there is a permissions issue or Salesforce-side automation triggered after the OpenFn insert operation?
One test to try… via the web browser, if you manually input the same value (e.g., "No access to water in school") into the Why_tank_has_no_water__c field and then “save” the record, does the record save? Or does Salesforce provide any error message/feedback?
Yeah it’s pretty strange. I’m using insert. Here is the snippet. I chunked the records because I was running into timeout issues when working with the entire array at once.
fn(state => {
let array = state.filteredNewMETankRecords
let chunkMETankRecordsArray = []
const chunkSize = 10;
for (let i = 0; i < array.length; i += chunkSize) {
const chunk = array.slice(i, i + chunkSize);
// do whatever
chunkMETankRecordsArray.push(chunk)
}
if (chunkMETankRecordsArray.length == 0 || chunkMETankRecordsArray == null || chunkMETankRecordsArray == undefined) {
console.log('No records to add')
} else {
console.log(`There are ${chunkMETankRecordsArray[0].length} records to add`)
}
return { ...state, chunkMETankRecordsArray }
})
each(
'$.chunkMETankRecordsArray[*]',
bulk(
'ME_tank_information__c',
'insert',
{ extIdField: state.objIDMapping['ME_tank_information__c'], failOnError: true, allowNoOp: true },
state => state.data
)
)
I’m able to update the field in the browser though.
@djohnson I see that in you’re job you’ve specified insert as your operation, but then it looks like you’re passing in an .extIdField… do you maybe want to use upsert instead?
In Salesforce “insert” operations will always create records and do not support checking for existing records using an externalId. If you want to insert or update, then use the “upsert” operation (where you must specify an externalId).
Check out the adaptor docs for more examples, but I think that issue might be that you’re using insert + passing an externalId. Can you try either removing the extIdField argument or changing the operation to upsert?
Or @mtuchi do you spot anything else here that might be off?
I was using insert here because I have to create records. The records are inserted to the ME_tank_information__c object which lives under another object. The record for the parent object is created during the same workflow, so I need to fetch the ID of that newly created record and insert the ME_tank_information__c records there. Is this the right way of achieving this?
@djohnson Not quite… so extIdField is for the target record you’re trying to import. In the below example, Patient_ID__c is the external Id for Patient__c:
bulk(
"Patient__c",
"upsert",
{ extIdField: "Patient_ID__c" },
[
{
Patient_ID__c: state.data.patientUid,
Name: state.data.patientName
},
]
);
When you want to link a child record to the parent, you need to map the relationship in the payload body (e.g., LookupField__r.ParentRecordExtId__c), and not specify it is a separate argument in the bulk() function. For example:
bulk(
"Patient__c",
"upsert",
{ extIdField: "Patient_ID__c" },
[
{
Patient_ID__c: state.data.patientUid,
Name: state.data.patientName,
//link to Patient to parent HH using external id of parent record
Household__r.HH_ID__c: state.data.householdId
},
]
);
Alternatively, you can first query Salesforce to get back the record id of the parent record (e.g., householdId)… and then directly map this when you create the patient - something like this:
bulk(
"Patient__c",
"upsert",
{ extIdField: "Patient_ID__c" },
[
{
Patient_ID__c: state.data.patientUid,
Name: state.data.patientName,
Household__c: householdId
},
]
);
Check out this Salesforce post for more background info on Salesforce relationship fields and notation for these. And remember that bulk() is using the Salesforce Bulk API in case you want to look at those official docs for more on Salesforce rules.
And again, the bulk() examples in the OpenFn Adaptor docs also show this mapping notation in action.
Thanks for the examples. I will test these and see if the problem disappears.
Hope they helped, @djohnson !
We’ve just added a “mark as solution” button to the forum. If @aleksa-krolls 's examples do the trick would you mind clicking the little grey check box (near the heart) at the bottom of her post so that others can easily find it?
And if not… let us know what errors you’re seeing and we’ll try again ![]()
Thanks Taylor, I’ve marked it as a solution.
1 Like
Hi, unfortunately, I am still having problems with inserting records. I am using the following
fn(state => {
let array = state.filteredGRRecords
let chunkGRRecordsArray = []
const chunkSize = 200;
for (let i = 0; i < array.length; i += chunkSize) {
const chunk = array.slice(i, i + chunkSize);
// do whatever
chunkGRRecordsArray.push(chunk)
}
if (chunkGRRecordsArray.length == 0 || chunkGRRecordsArray == null || chunkGRRecordsArray == undefined) {
console.log('No GR records to insert')
} else {
console.log(`Inserting ${chunkGRRecordsArray[0].length} GR records`)
}
return { ...state, chunkGRRecordsArray }
})
each(
'$.chunkGRRecordsArray[*]',
bulk(
'GR_Engagement__c',
'insert',
{ failOnError: true },
state => state.data
)
)
And here is part of state.data
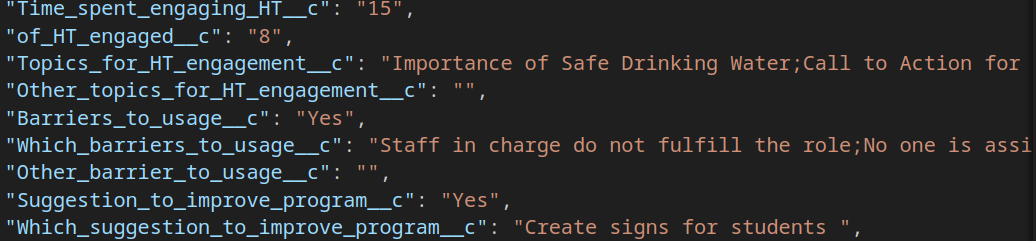
But for some reason, some of these fields are not updated in Salesforce.
Changing to upsert doesn’t work because there is no External ID field for this object. Is the issue with state => state.data?
Hi @djohnson ,
From your job code, everything looks fine. However, it might help to get more clarity from the Salesforce response. Does the response contain any errors? You can find the response details in state.references.
I’ve cleaned up your job code a bit and switched to using the insert function since you’re already chunking records by 200, which is the standard batch size. Note that the Salesforce adaptor already includes a helper function called chunk() to handle record chunking.
fn((state) => {
state.chunkGRRecordsArray = chunk(state.filteredGRRecords, 200);
if (!state.chunkGRRecordsArray || state.chunkGRRecordsArray.length === 0) {
console.log("No GR records to insert");
return state;
}
console.log(`${state.chunkGRRecordsArray.length} chunks of GR records`);
return state;
});
each(
$.chunkGRRecordsArray,
insert("GR_Engagement__c", (state) => {
console.log(`Inserting ${state.data.length} GR records`);
return state.data;
})
);
A couple of things to note:
- The
chunk()function provided by the adaptor simplifies chunking records into manageable sizes, so you don’t need to implement it from scratch. - If you’re dealing with a large number of records, consider using the
bulkoperation. The Bulk API supports a batch size of up to 10,000 records and automatically chunks records if the dataset exceeds this limit.bulk(“GR_Engagement__c”, “insert”, { failOnError: true }, $.filteredGRRecords)
- For smaller datasets
(<=200)or real-time operations, your current approach withinsertworks well.
Let me know if you need further help! ![]()
1 Like
Unfortunately, there aren’t any errors in state.references
{
"logger": {},
"references": [
[
{
"id": "a3fRo000000SLfpIAG",
"success": true,
"errors": []
},
{
"id": "a3fRo000000SLfqIAG",
"success": true,
"errors": []
}
]
Thanks for code suggestions. I switched to chunking and each after using bulk because of timeout issues.
Thanks, your suggestion worked! The fields appear to be updated in Salesforce.

Do you know what was wrong the previous code?
1 Like
@djohnson
In most cases the Bulk operation timeout because of Salesforce API limits and Governance. Bulk operations must adhere to API limits, such as the number of batches or records that can be processed per 24-hour period. High API usage across the org can introduce delays.
But you can increase the pollTimeout and pollInterval incase of timeout issues. See bulk options docs here
Thanks for the explanation, but I was wondering more about why some fields update and others don’t.
Hey @djohnson - it’s hard to say why those fields weren’t updating offhand without a better understanding of your system and closer inspection of the data you attempted sending. Mtuchi’s suggested solution uses the regular REST api to insert records, and not the Bulk api (which create async data import jobs in salesforce), so Saleforce does processes these bulk requests a little differently.
Typically, a bulk API job is considered “successful” if the records themselves are imported in Salesforce without critical errors (e.g., validation rule failures or missing required fields). However, if there are issues with specific fields in the data or the target Salesforce configuration (e.g., field-level security, read-only fields, or data type mismatches), those fields may not update while the import job still reports as successful and I’ve noticed these field-level issues don’t always throw an error in the bulk api response.
Some troubleshooting tips I’d explore:
- Go to
Setup>Bulk Data Load Jobsto inspect the data sent by OpenFn to your Salesforce org and the response… you can download csv files of the requests and responses sent via the API to verify what you’re seeing in the OpenFn logs. See Salesforce docs for more on this monitoring interface. - Consider if there is any salesforce-side automation triggered after insert. Downstream automation, like Apex Triggers, Flows, or Processes, could override or fail to update specific fields, depending on their logic. You could try setting up Debug Logs on the Salesforce-side to track downstream automation action to discover if they might be the culprit.
- In your original job code, also did you try adding a
console.log()to troubleshoot whatstate.datalooked like before it was sent to the salesforce api? For example:
each(
'$.chunkGRRecordsArray[*]',
bulk(
'GR_Engagement__c',
'insert',
{ failOnError: true },
state => {
console.log('payload sent:', state.data); // Logs the data to the console
return state.data;
}
)
);
- I think this might also still be an issue, even if the latest bulk api version, in case this happens to be the case with your data.
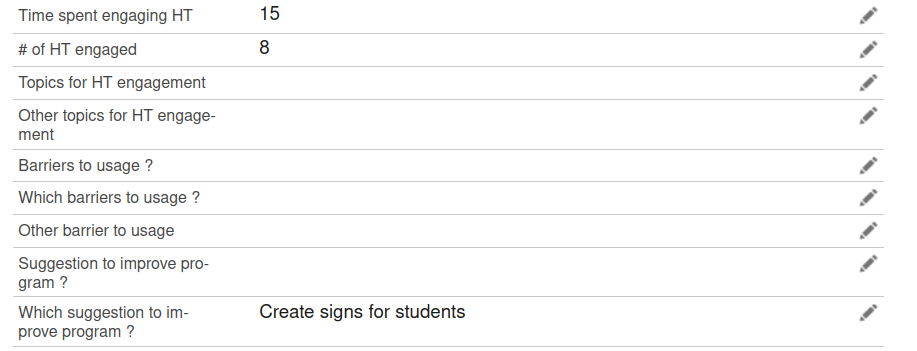
Thanks for your suggestions. I will try them out and get back to you. In the meantime, I noticed that the fetchSubmissions function in the surveycto adaptor doesn’t retrieve all the fields. This may be part of the reason why the fields I expected to update weren’t updated.
Here is a screenshot from downloading the csv from the SurveyCTO console.

And here is the json response for the same form
"zone_id": "a2C2M000005G8Sx",
...
"engagement_type": "1",
"met_officer": "",
"no_met_officer": "",
"met_other": "",
"met_other_who": "",
"topics": "",
"topics_1": "",
"topics_2": "",
"topics_3": "",
"topics_4": "",
"topics_5": "",
"topics_6": "",
"topics_997": "",
"topics_other": ""
topics is filled in the csv, but not in the json response. Do you know what could be causing this?
So from the result log from Setup > Bulk Data Load Jobs. It looks like everything was created successfully. But when I look at the request log, topics is still not being mapped
![]()
I also made sure that each object contains all the keys using
let fullKeys = Object.keys(anotherObj)
let fullObj = {}
for (const key of fullKeys) {
fullObj[key] = '';
}
GRRecords.forEach(e => {
for (var key in fullObj) {
e[key] = e[key] || fullObj[key]
}
})
where anotherObj contains all keys.
I also confirmed that there are no triggers or flows touching this object.
The payload from console.log seems to be correct, so I think the issue is that values from some fields aren’t being retrieved with fetchSubmissions. See here for an example of what is fetched using another API
'zone_id': 'a2C2M000005G8Sx',
...
'engagement_type': '1',
'topics_1': '1',
'topics_2': '1',
'topics_3': '1',
'topics_4': '1',
'topics_5': '1',
'topics_6': '1',
What’s strange is that in some cases, it correctly returns the values for topics. So I’m not sure where the issue is. I’m happy to jump on a call about this if it’s easier.
Looking like @djohnson it’s been a long time since anyone has used the surveycto adaptor, so we’ll have to check it out - I will flag to our product team.
If you’re in a hurry, in the meantime I might recommend using either (a) the generic request() function, or (b) the http adaptor until we can sort this out.
FYI see here for our adaptor source code in case you want to check out what http requests it sends behind the scenes when fetchSubmissions() is called. Your GET request will probably look something like this:
GET ‘https://servername.surveycto.com/api/v2/forms/data/wide/json/formid?date=[${dateToFilterBy}]’
Thanks, I will give those a try.