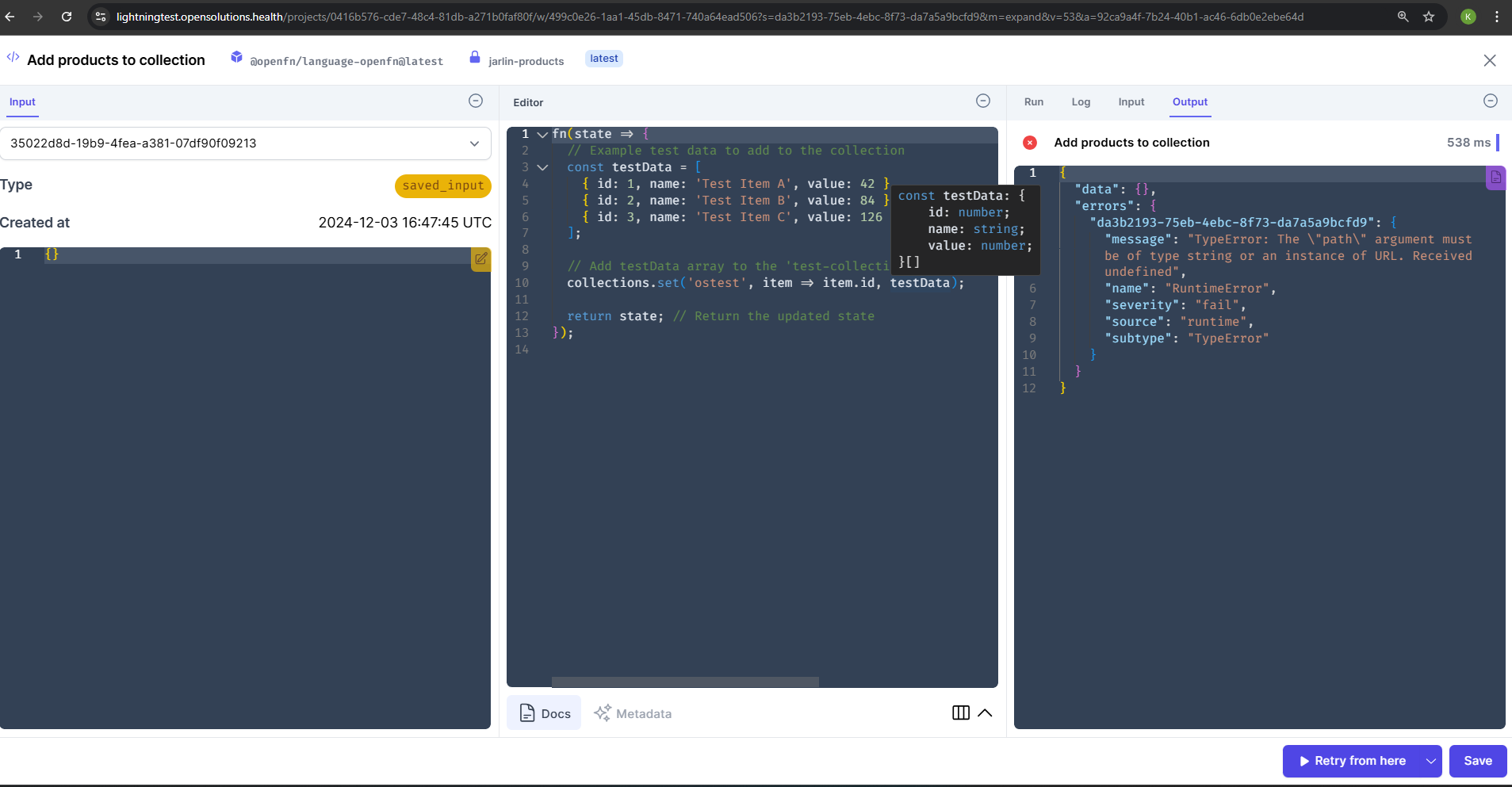
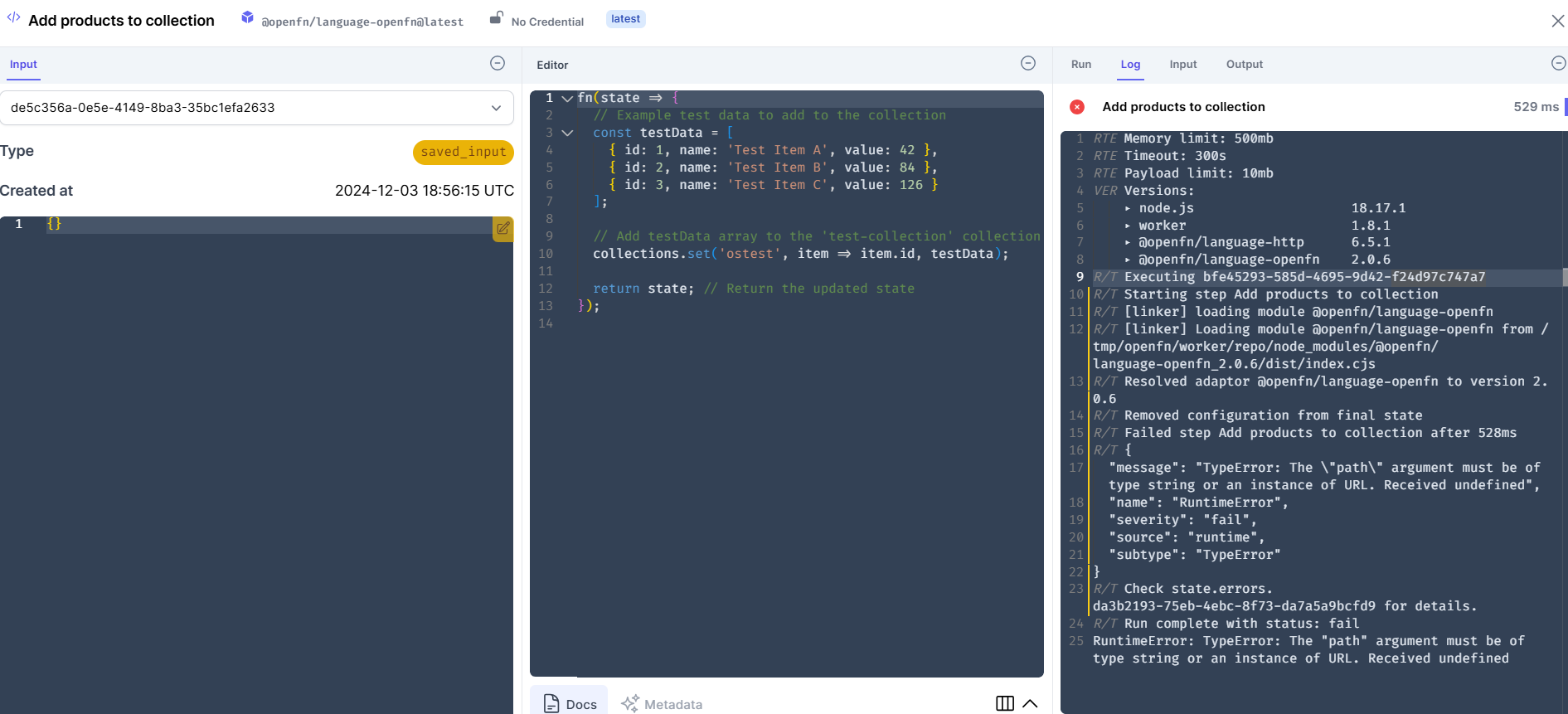
What is the most effective way to implement this workflow in , where:
Job 1 makes an API call to retrieve data on the first iteration.
Job 2 pushes the data to another application via API.
On subsequent iterations, Job 1 pulls new data via the API and compares it with the previously retrieved data to ensure only updated information is pushed by Job 2?
Initially I designed the work flow to pull the data from the application where the data is being pushed to and use this to compare to the data being pulled. I am just wondering if there is a more effective to this as i mentioned above.
Hmm… well is this a cron-triggered workflow? If yes, then you can pass state between successful runs (see docs), so in theory you could write the dataRetrieved to the final state of the job, to then access and compare new data with with in the subsequent run. However, you’ll need to be careful about managing the state over time.
hey @joe@taylordowns2000 any recommendations or feedback on this approach? And maybe could this be a use case for collections?
(Kiefer, collections is a new feature just released that provides a temporary data store in OpenFn. @ayodele should be sharing more about this new feature in the community next week!)
Yeah collections sounds perfect for this! You can “cache” a list of ids of the data you’ve already processed, and compare and update that on every run to ensure you avoid duplicates.
We’ve got a few outstanding issues on collections which I’ll be fixing next week - but it should work well for you already. I’m happy to help here if you have any questions or difficulties!
Hey @Kiefer - I’m not aware of any problems you’ll have with a local Docker build. It should all just work as usual. There’s an endpoint at /collections that needs to be exposed but I don’t think you’d need any special handling for that.
But of course do let us know if you encounter any difficulties!
@Kiefer you also need to be a “super admin” user in order to access and create new collections - again see docs. If you’re running into issues, let us know what you are/aren’t seeing and what version of lightning you’re running locally.
Oh hang on - I just re-read your post an my eyes pricked up on "The credentials was created and configured according to the documentation.
You don’t need to create any credential for collections - Lightning takes care of that for you. So if you’ve created a special credential, the next step would be to remove it and run again.